
Atlassian Guard helps organisations protect high-value data across their Atlassian sites. Recent work expanded that protection from newly created content to the years of Confluence pages and Jira issues many organisations already rely on every day.
My role was design manager for the team. I helped shape the product direction, supported designers through complex interaction and policy decisions, gave hands-on feedback, and worked with cross-functional partners to keep the experience understandable for enterprise admins.
The problem
Guard could already detect sensitive information in new content, but sensitive data can also sit inside years, or decades, of existing Confluence pages and Jira issues. That old content still matters. It can be searched, shared, referenced and surfaced through newer AI-powered experiences.
For admins, the challenge was not just detection. They needed visibility into where sensitive data lived, confidence that the right content could be classified, and controls for how classification changes should work across their organisation.
What the team shipped
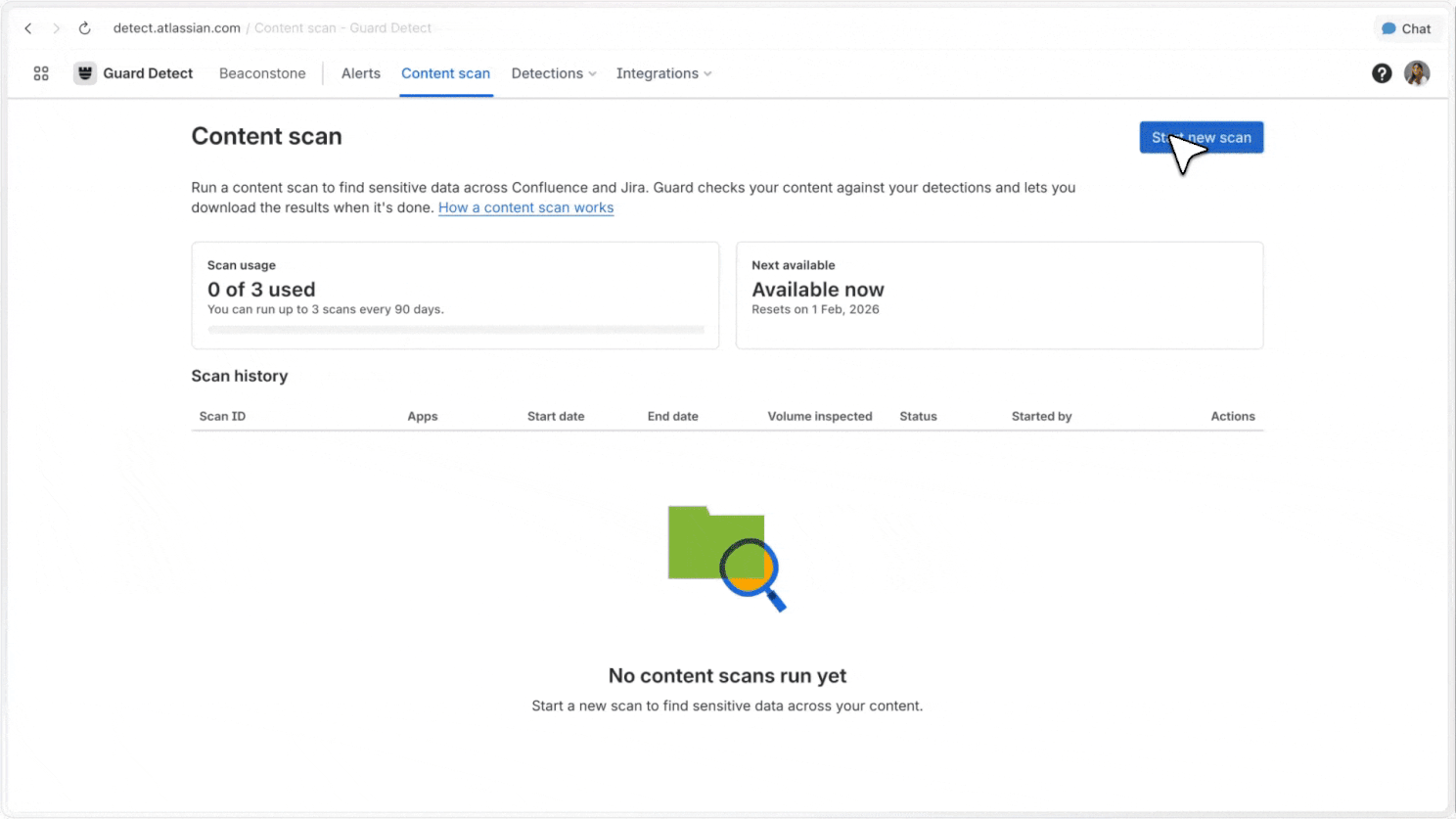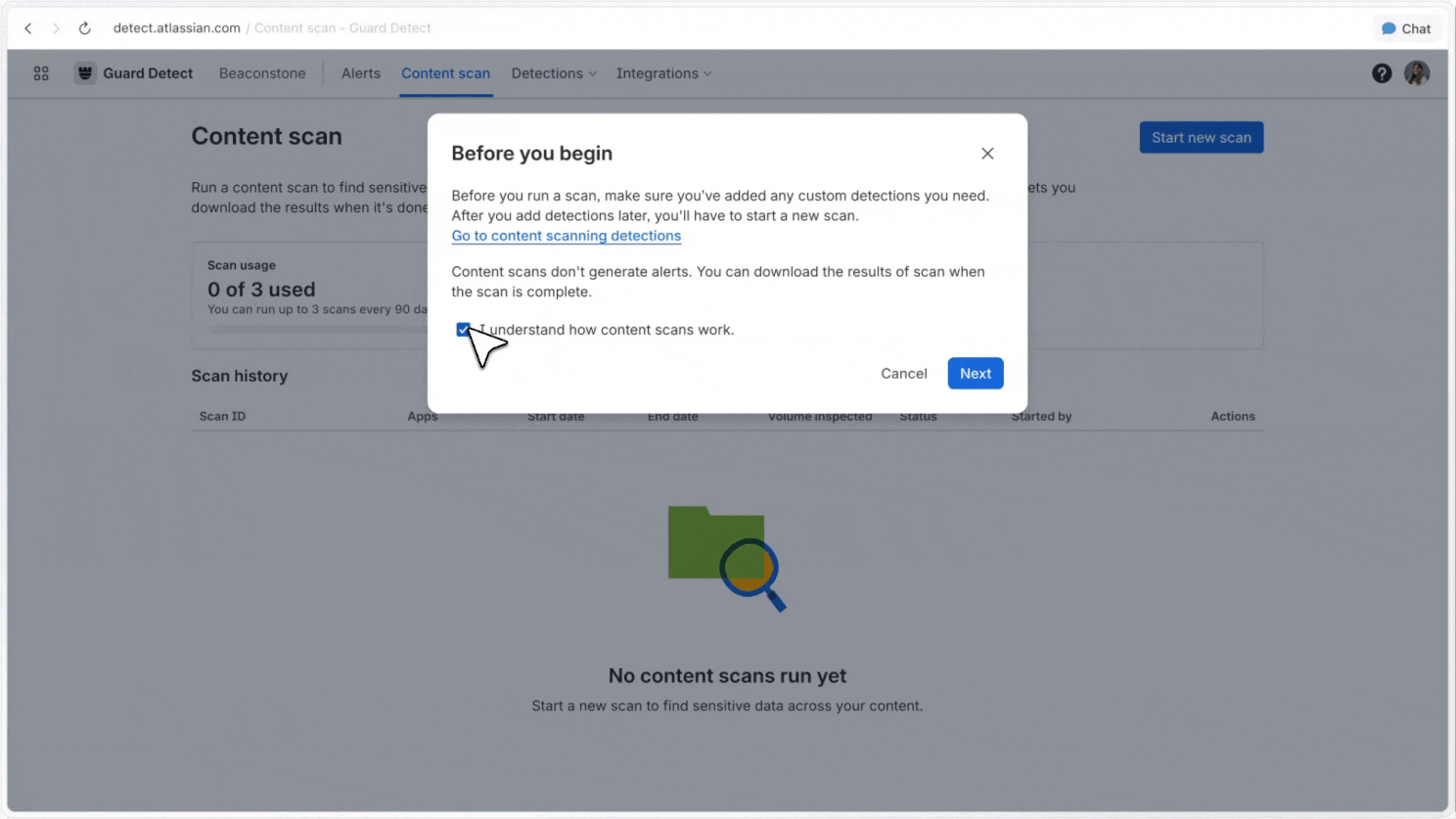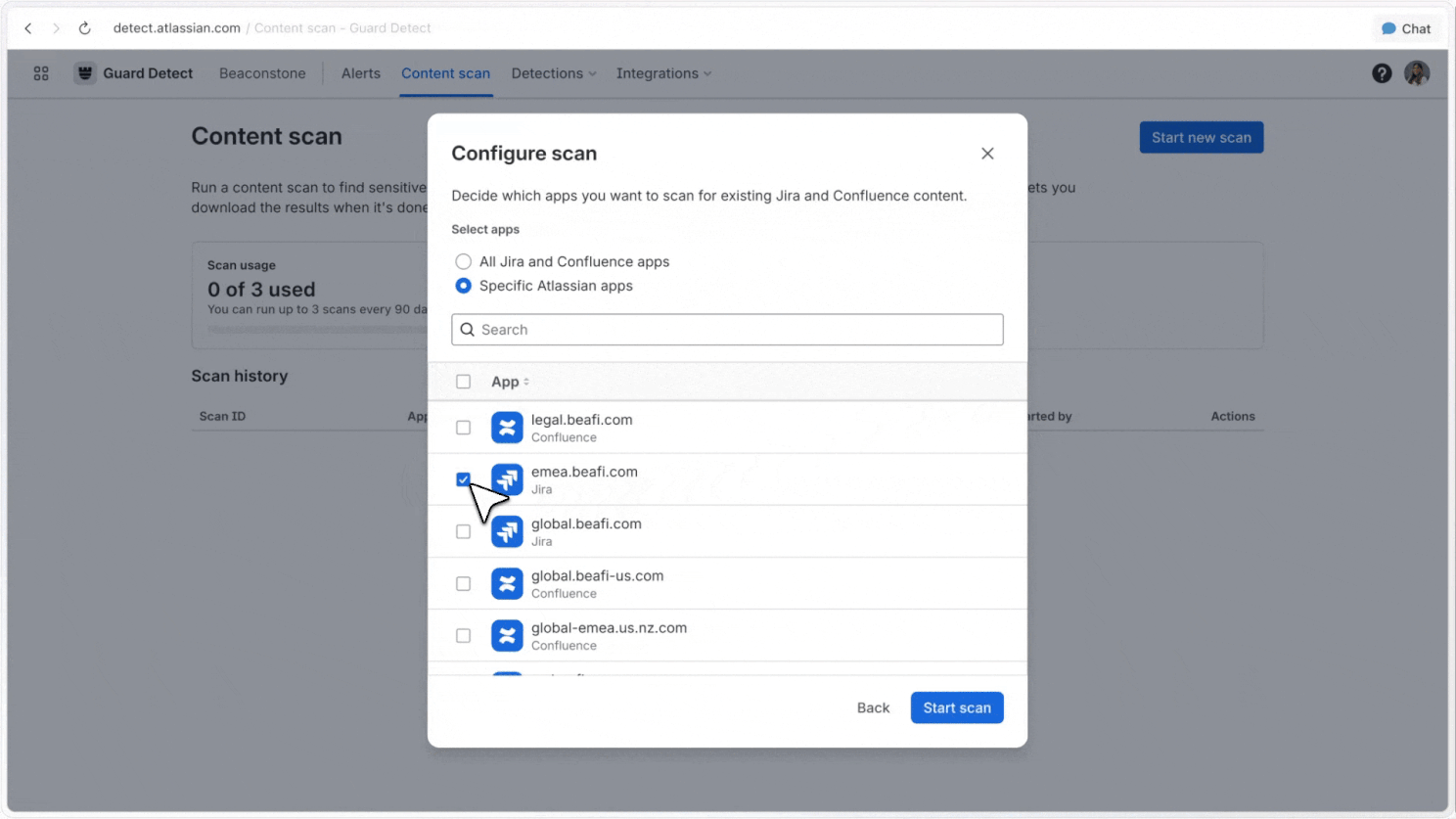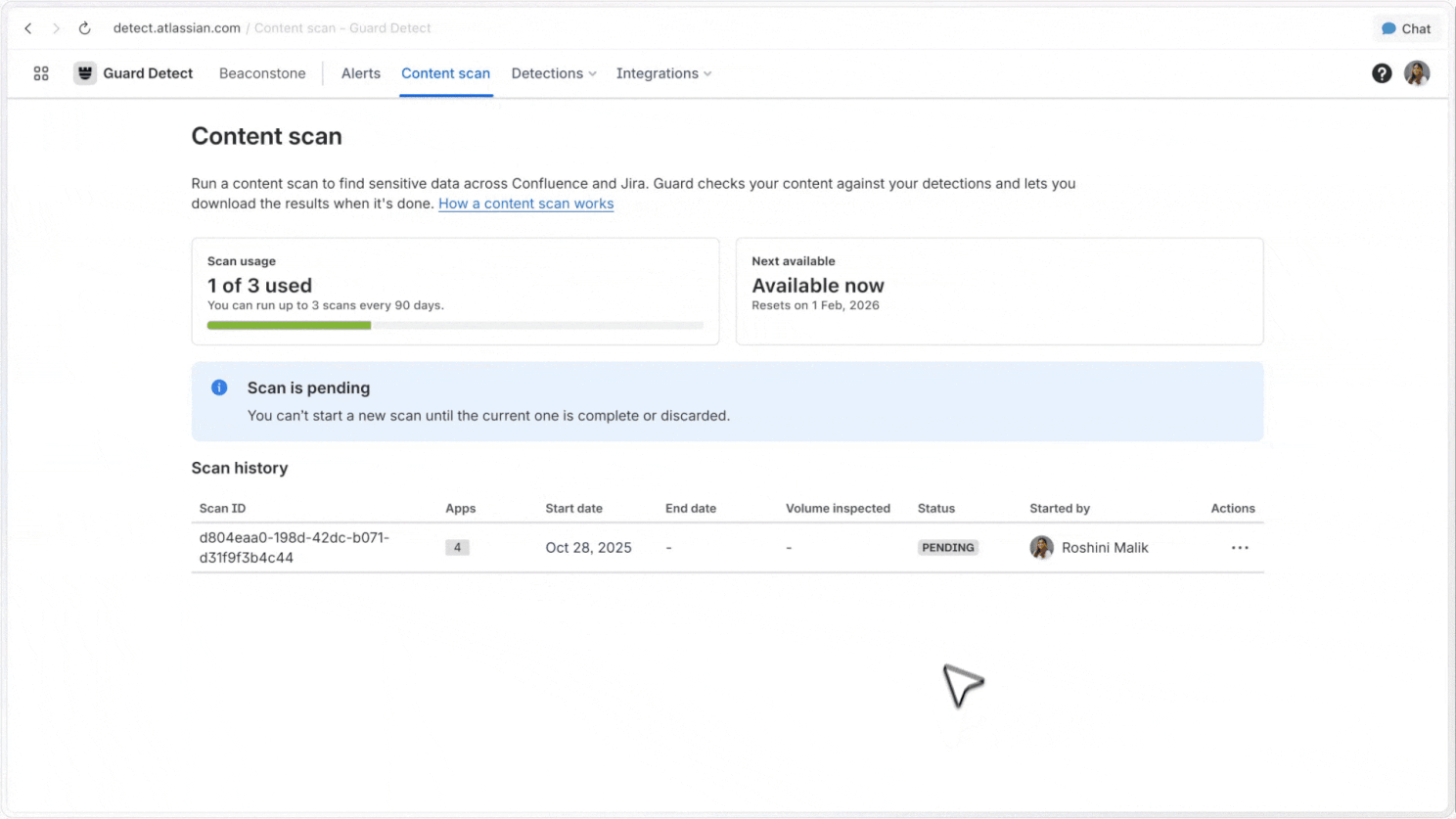
Full-site scans
Admins can scan full Jira and Confluence sites, covering historical content as well as new content, to understand where sensitive data appears across large sites.
Classification rules
Rules can automatically classify content based on the sensitivity of the information detected. For example, content containing financial data can be classified as confidential.
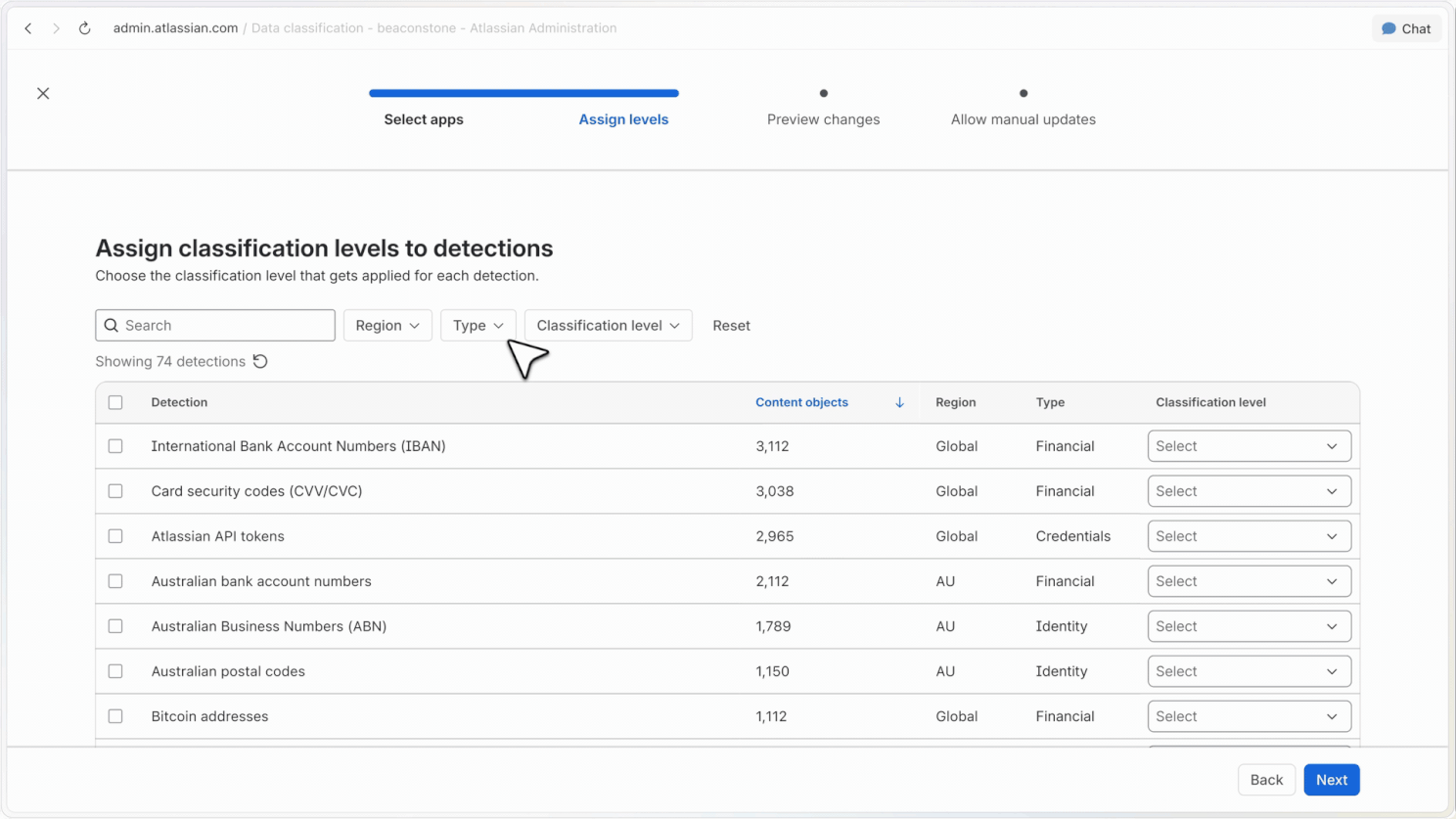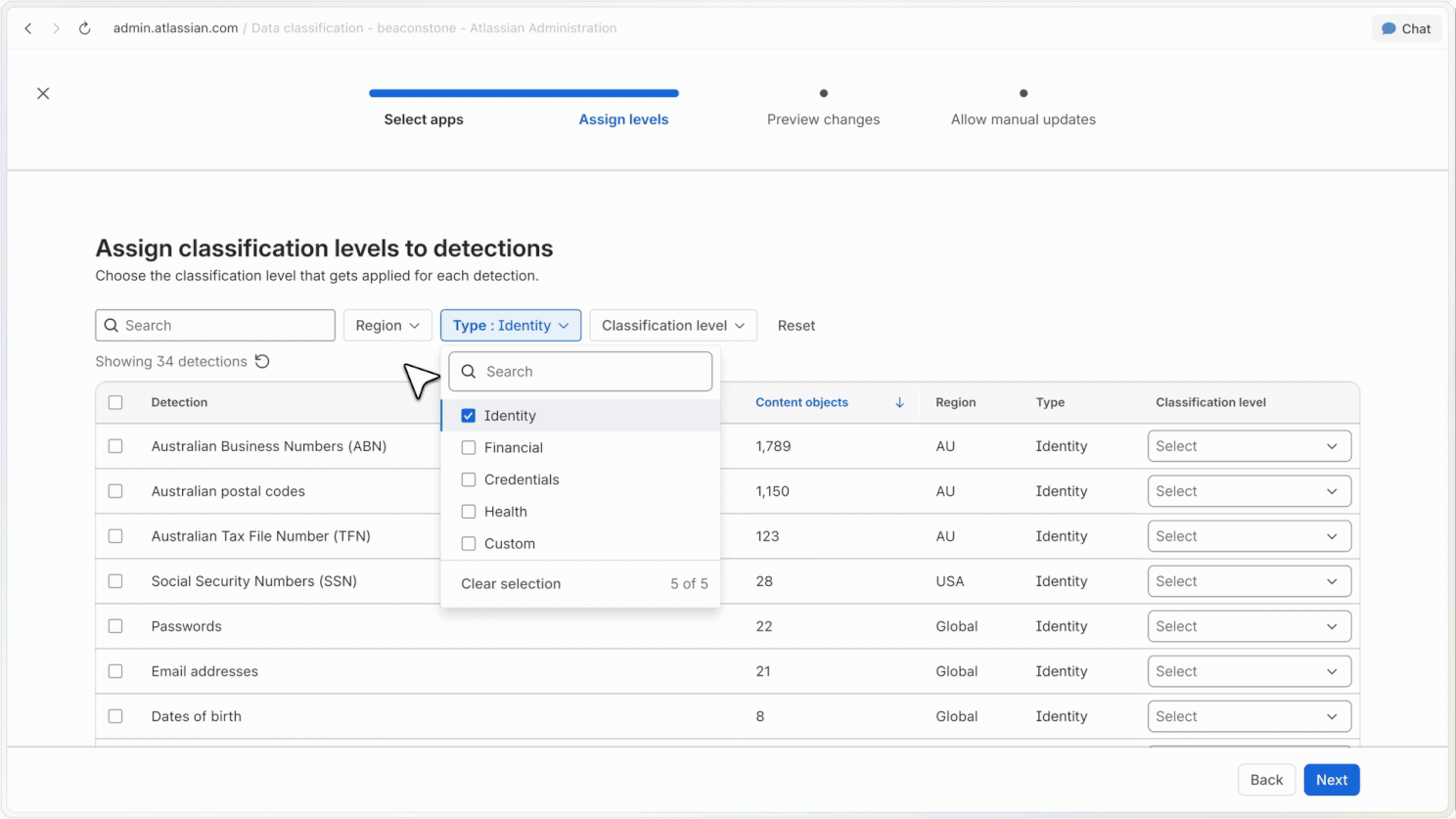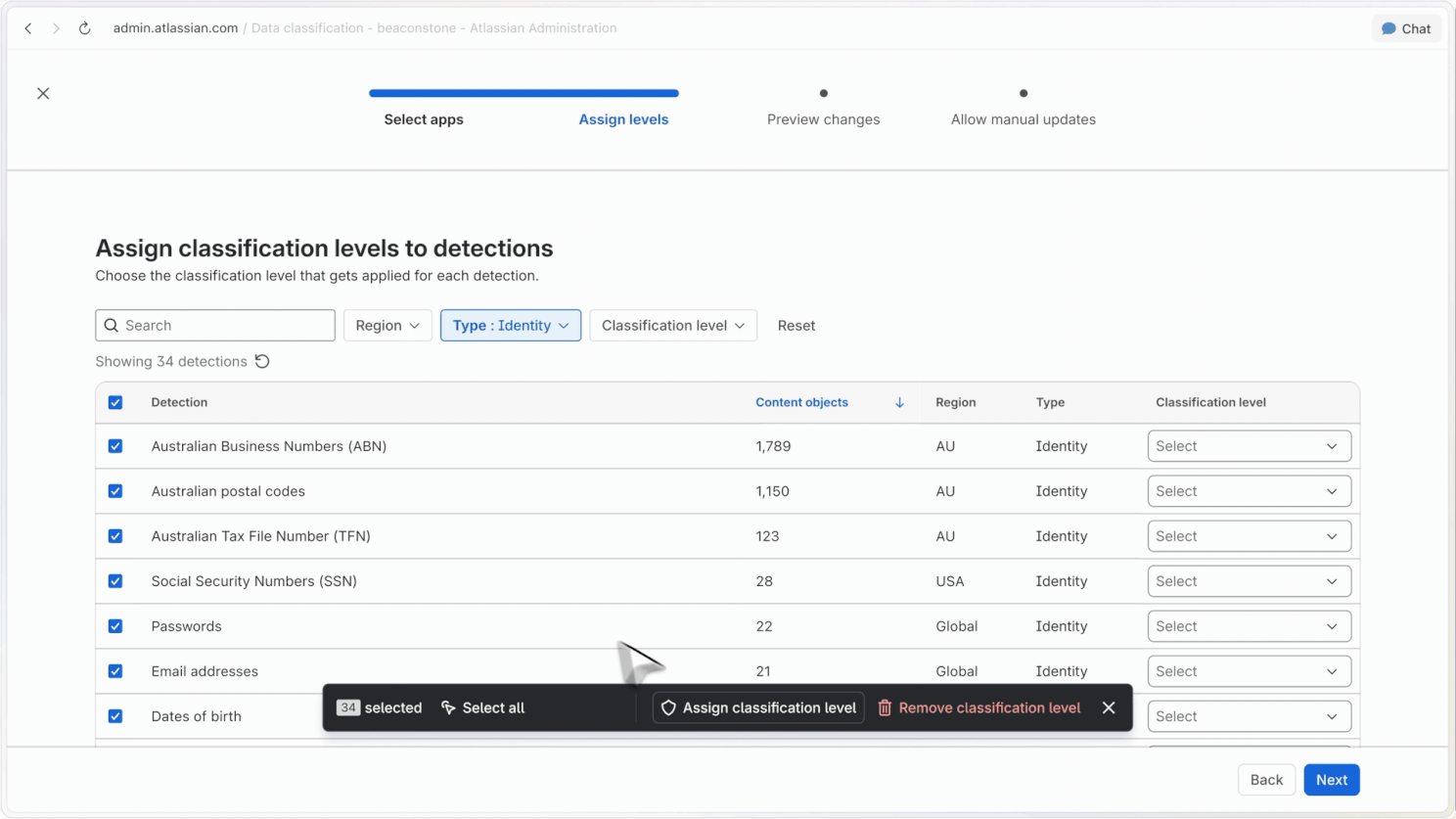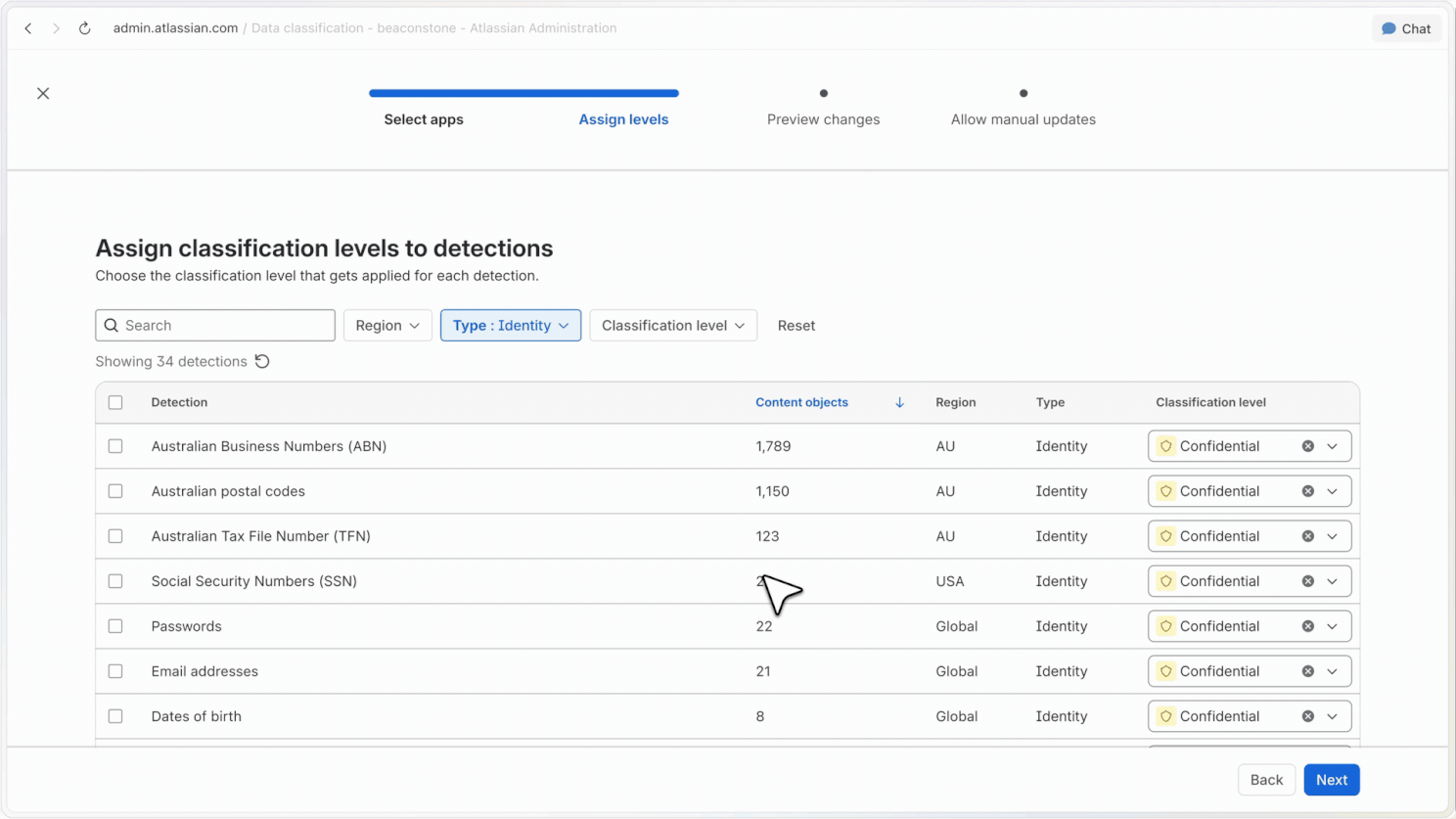
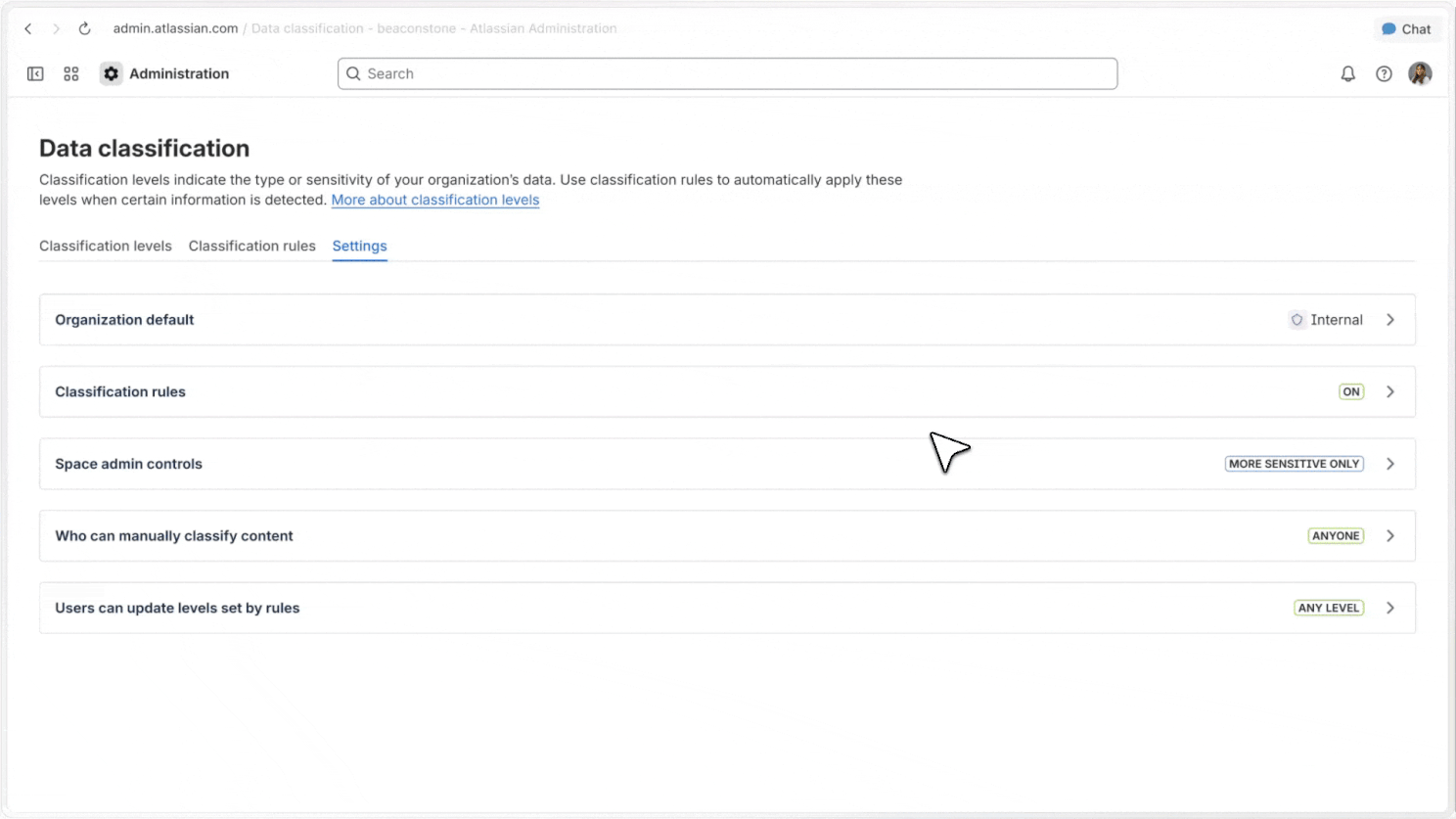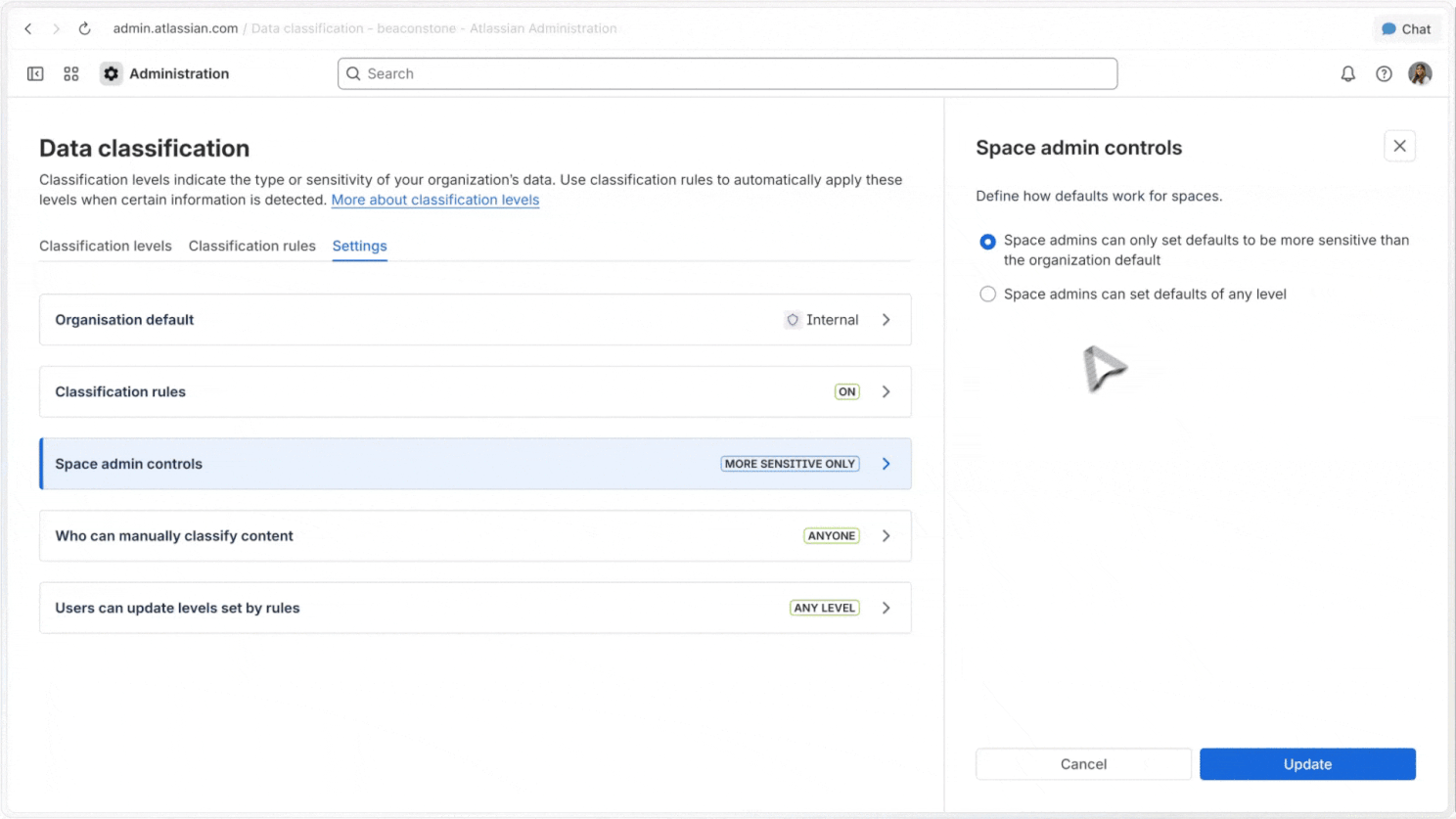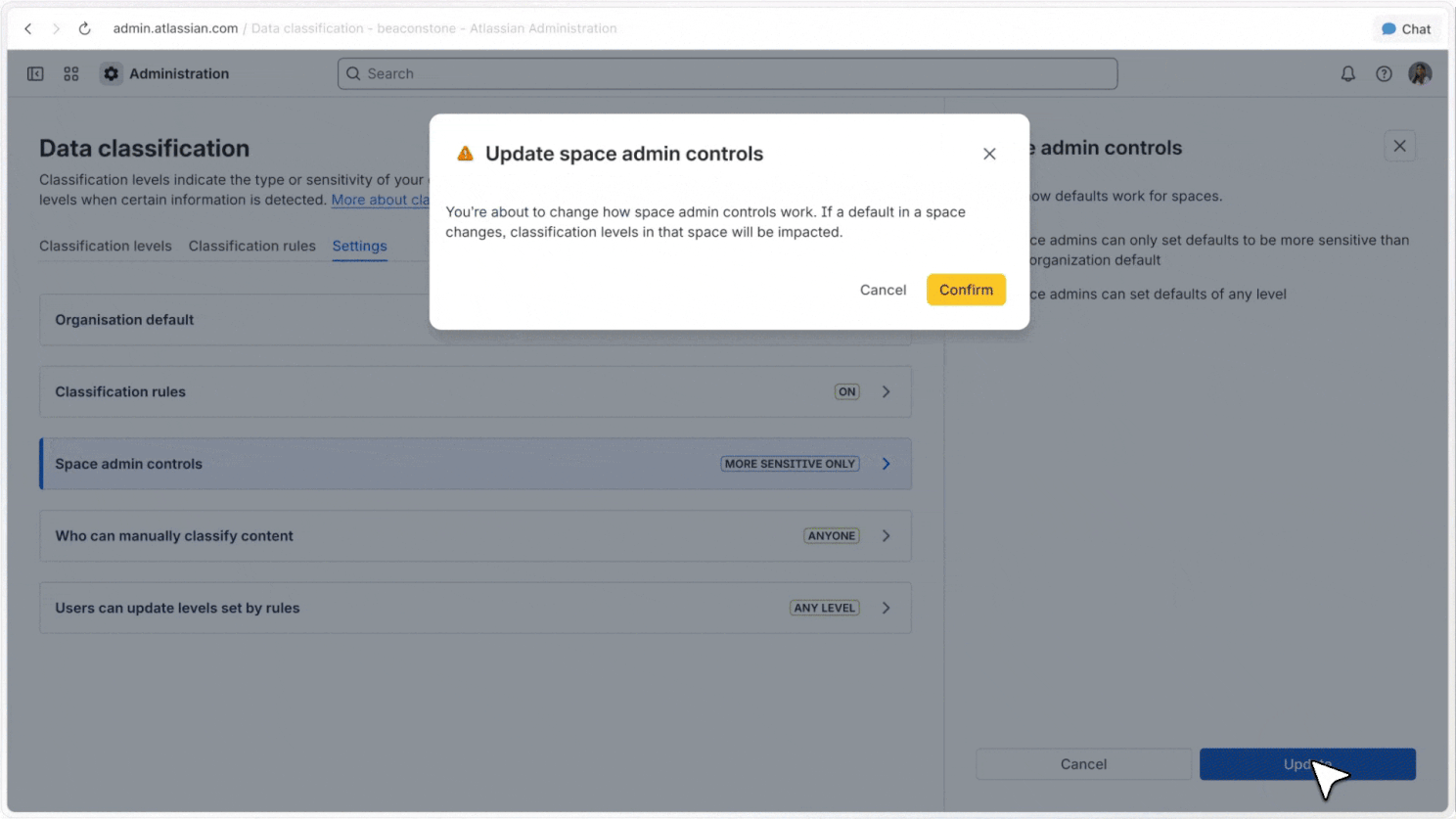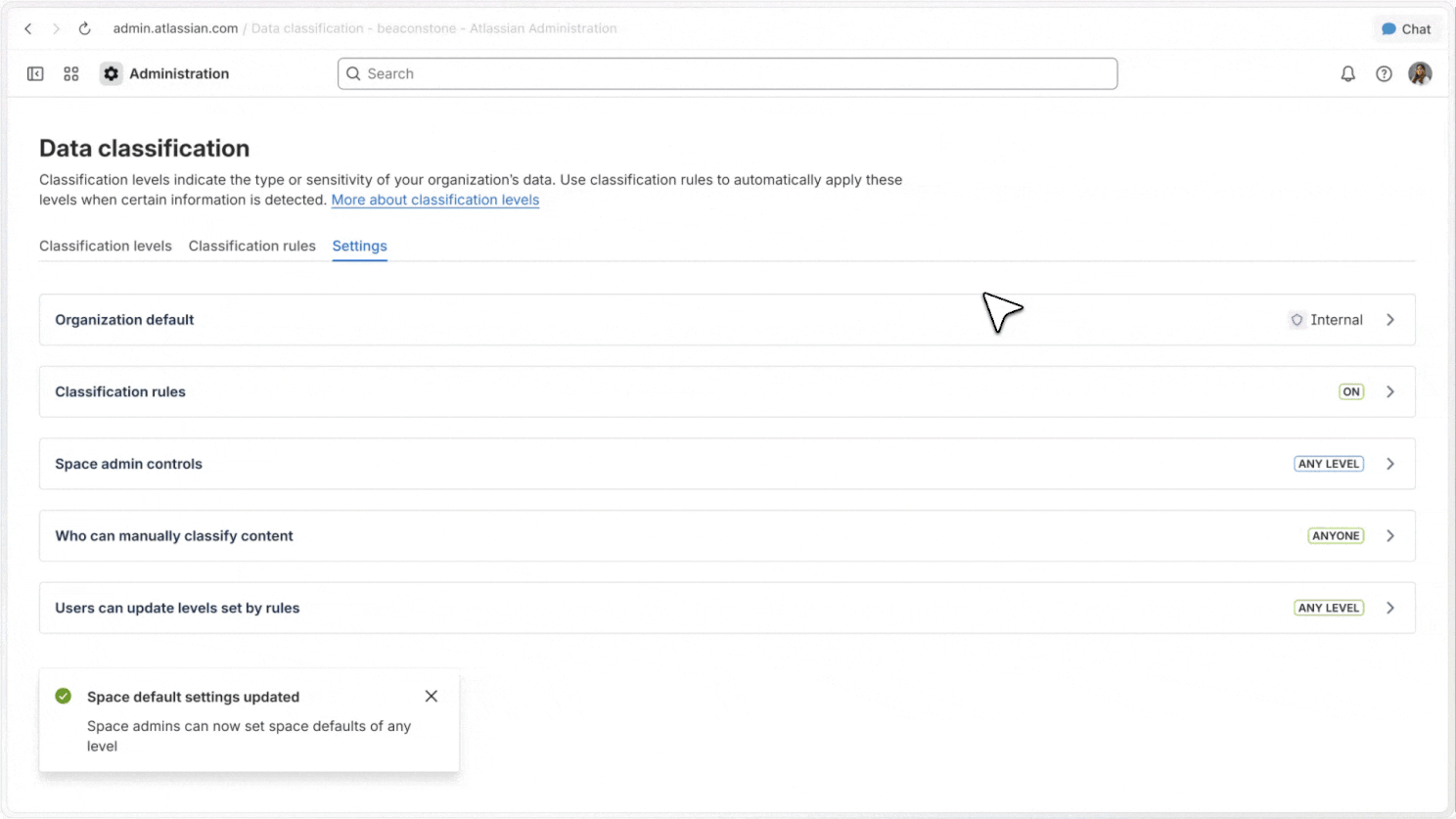
Reclassification controls
Admins can define who can reclassify content, how those changes work, and what defaults apply across their organisation.
Design leadership
This work sat at the intersection of security, admin control, content governance and AI readiness. My contribution was to help the team make those concerns feel coherent rather than fragmented.
I focused on helping the team frame the admin problem clearly, pressure-test flows against enterprise edge cases, and make trade-offs between automation, transparency and control. The goal was to give admins enough power to govern sensitive data without turning the experience into a maze of settings.
Why it mattered
Finding sensitive information after it has spread through a large knowledge base is hard. Giving admins a way to scan, classify and control that content helps organisations move from reactive clean-up to more proactive data governance.
It also makes AI adoption safer. When organisations have better visibility and controls around sensitive information, they can use tools like Rovo with more confidence that private or high-risk content will not be surfaced to the wrong people.